
篡改在英文文献中常用manipulation、tamper、forgery这三个词表达。广义上的图像篡改指的是对原始图像做了改动的操作,这种改动操可以是:图像属性改变、图像格式转换、形态学处理、模糊处理、缩放剪裁(seam carving)等等。
图像篡改类别可以粗略划分为图像处理操作(manipulation)和图像篡改操作(tamper)两类(按英文直译,manipulation是操作的意思,此类篡改有点类似仅对图像做非内容性的处理,而tamper按直译,则是对图像做了内容性的处理):
Manipulation:滤波处理(如中值滤波 Median Filtering)、模糊处理(如高斯模糊 Gaussian Blurring)、添加噪声(如高斯白噪声 Additive White Gaussian Noise)、重采样(Resampling)、压缩处理(如JPEG压缩 JPEG Compression)等。
Tamper :删除(Removal)、添加(Adding)、复制(Copy-move)、拼接(Splicing)等。
图像篡改检测技术涉及以下领域:
- 司法鉴定和公安办案中照片的真伪鉴定
- 保险事故中照片的真伪鉴别
- 新闻摄影和赛事照片的真伪鉴别
- 电子交易票据图像的真伪鉴别
概述
篡改检测问题实际上就是要检测出图像当中做过改动的区域。近几年,学术上更趋于集中研究splicing、copy-move、removal这三个类型图像篡改的检测问题。

如上图:
- 图像拼接(Splicing):将一张图的内容抠下来贴在另一张图上;
- 复制移动(Copy-move):将同一张图上的内容复制粘贴到另一个位置;
- 擦除填充(removal):操作将同一张图上的内容擦除掉。

此外,对图像篡改检测的研究也有专门只针对人脸和文字的,上图上幅来自Andreas Rossler et al., 2018,是专门针对人脸篡改的检测;下幅来自Yulia S. Chernyshova et al., 2018,是专门针对文字篡改的检测。
数据集
| 数据集 | 图片数 | 篡改类型 | 描述 | 链接 |
|---|---|---|---|---|
| CASIA v1.0/v2.0 | 921/5123 | splicing; copy move; | 只提供原图、篡改图,不包含GroundTruth; | Kaggle(提供原图、篡改图); @namtpham(在原图、篡改图的基础上提供了GroundTruth) |
| Columbia | 183 | splicing; | 基于未压缩图像的拼接,提供GroundTruth; | Columbia Uncompressed Image Splicing Detection Evaluation Dataset |
| NIST 2016 | 564 | splicing; copy move; removal; | 提供GroundTruth; | NIST Public Media Forensics Data |
| COVERAGE | 100 | copy move | 专注于copy-move,提供GroundTruth; | Coverage |
| Pawel | 220 | object-insertion; removal | 手工篡改数据集,非常走心的; | Pawel korus-Realistic Tampering Dataset |
| PS-Battles | 40.2G | 类型诸多 | PS社区手工篡改,篡改类型多,篡改更真实; | Ps Battle DataSet; 原论文 |
百度网盘链接:(包含 NIST, COVERAGE, Columbia)
链接:https://pan.baidu.com/s/1Rn18JLDV7WviUvP8UsRZVQ
提取码:ptur
Related Work
人类在识别复制移动方面可能比检测拼接和移除更好。这是因为在复制移动图像中,人眼可以感觉到类似物体的重复。对于拼接和移除图像,人类在很大程度上依靠寻找明显的边缘不连续和照明不一致来确定是否发生了篡改。因此,当在经过良好篡改的图像中视觉上看不到不一致之处时,人类将无法检测到篡改。之前传统的图像处理方法提出了探索边缘不连续和照明不一致性的算法,以协助并超越人类在篡改检测任务中的能力。
当前深度学习的图像篡改区域定位方法主要有以下三种方向:
- 将篡改区域定位认为是像素级的二分类,采用图像分割的算法来定位篡改区域。
- 将篡改区域定位当作是目标检测任务,采用目标检测算法来定位篡改区域。
- 将篡改区域定位当作是局部异常检测,采用CNN + LSTM网络检测图像中的局部异常。
接下来总结近几年这三个方向具有代表性的图像篡改区域定位方法。
RGB-N
Learning Rich Features for Image Manipulation Detection
发表在:CVPR 2018
论文:https://arxiv.org/abs/1805.04953
代码:https://github.com/LarryJiang134/Image_manipulation_detection
类型:拼接、移除
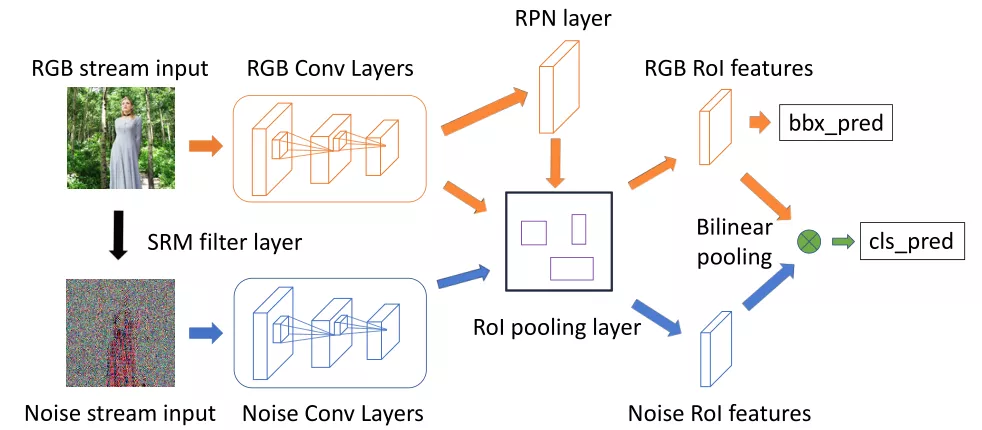
方法:提出了一种双流的Faster R-CNN网络,给定manipulated image,对其进行端到端的训练,以便检测被篡改的区域。双流分别为RGB stream、noise stream。其中,RGB stream主要目的是从RGB图像输入中提取特征,从而发现篡改区域强烈对比差异,非自然的篡改边界等之类的tampering artifacts。Noise stream 主要利用噪声特征去发现在真实区域和篡改区域之间的噪声不一致性,噪声特征是从steganalysis rich model filter layer中提取的。之后,通过bilinear pooling layer融合两个流的特征,以便进一步结合这两种模态的空间信息。
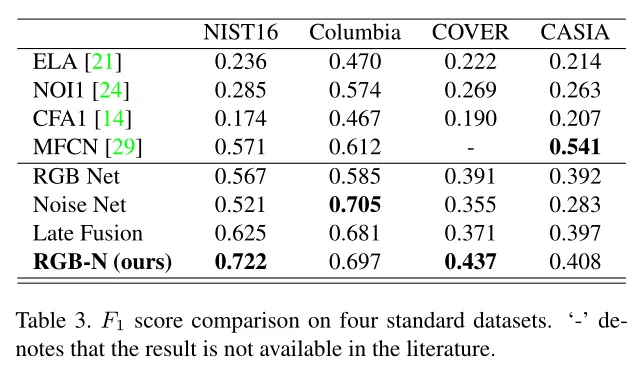
实验结果:CASIA 2.0作为训练集 CASIA1.0作为测试集。
简评:
- 该方法利用篡改区域与原图噪声不一致的线索,提出了双流Fast RCNN,这种方法的优势在于其具有很好的鲁棒性,这是由于当篡改者利用JEPG压缩或者resize隐藏时,噪声不一致的线索会更加突显出来,因此其具有很好的鲁棒性和抗干扰的能力。作者在文中分享了这一方法的局限也就是在复制移动的篡改方式下表现不太好,其原因有两个方面,首先,复制的区域来自同一张图像,这产生了相似的噪声分布,从而混淆了的噪声流。并且,两个区域通常具有相同的对比度。
ManTra-Net
ManTra-Net: Manipulation Tracing Network For Detection And Localization of Image Forgeries With Anomalous Features
发表在:CVPR2019
代码:https://github.com/ISICV/ManTraNet
类型:拼接、移除、复制粘贴
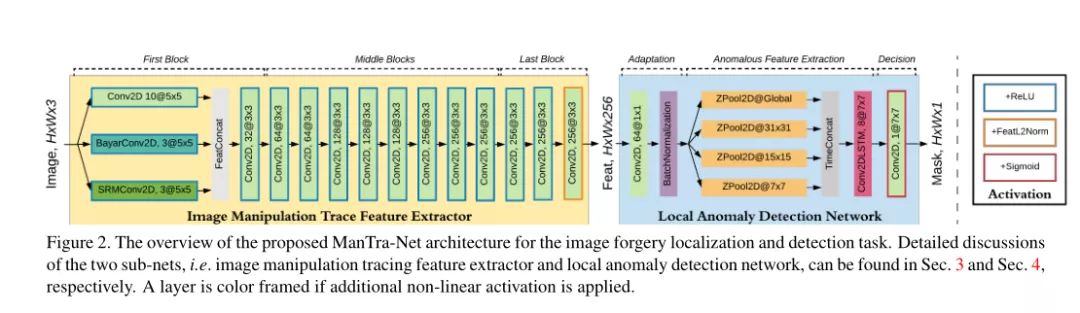
方法:作者提出了一个不需要额外的预处理和后处理的篡改检测网络ManTra-Net。此网络是一个全卷积网络,可以处理任意尺寸的图像和多种篡改类型。主要的贡献在于用一个自监督学习的方式从385篡改类型中学习特征,可以概括为压缩(JPEG一次、二次)、模糊(高斯、中值、小波)、形态学(膨胀 腐蚀)、插值(线性、二次、三次)、噪声(高斯、脉冲、均匀)、对比度、直方图均衡化等,并且将篡改定位问题当做一个局部异常点检测问题来解决。使用Z-score特征表示局部异常,使用long short-term memory solution进行评估。
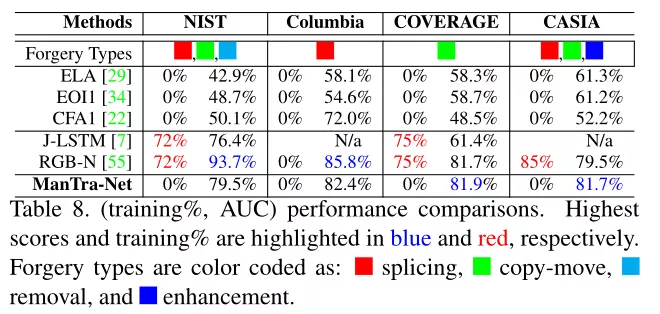
实验结果:CASIA 2.0作为训练集 CASIA1.0作为测试集。
简评:
- ManTra-Net 的创新之处在于设计了一个简单而有效的自我监督学习任务,以通过对385种图像操作类型进行分类来学习强大的图像操作轨迹。此外,我们将伪造定位问题公式化为局部异常检测问题,设计Z分数功能以捕获局部异常。ManTra-Net的优点主要在于它对于绝大多数的篡改攻击方式的有效果,因为它利用了自监督学习篡改的类型,因此有效的检测多种篡改方式,并且具有不错的鲁棒性,可以说是每个方式都有优势,但单独一种方式下不一定是最优的方法。
RRU-Net
RRU-Net: The Ringed Residual U-Net for Image Splicing Forgery Detection
发表在:CVPRW 2019
论文:https://ieeexplore.ieee.org/document/9025485
代码:https://github.com/yelusaleng/RRU-Net
类型:拼接
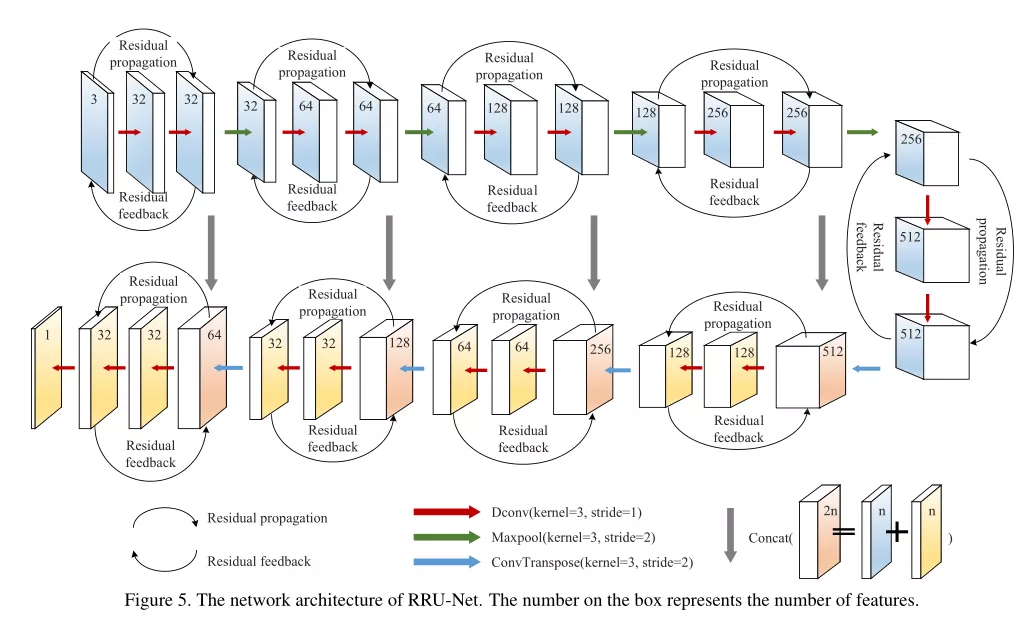
方法:作者基于 U-Net 提出了一种环状残差网络 RRU-Net 用于图像拼接伪造检测。RRU-Net 是一个端到端的图像本质属性分割网络,无需任何预处理和后处理即可完成伪造区域检测。RRU-Net 的核心思想是加强 CNN 的学习方式,并由CNN中残差的传播和反馈过程实现。残差传播调用输入的特征信息以解决更深层网络中的梯度退化问题;残差反馈合并输入特征信息,使未篡改区域和篡改区域之间的图像属性差异更加明显。
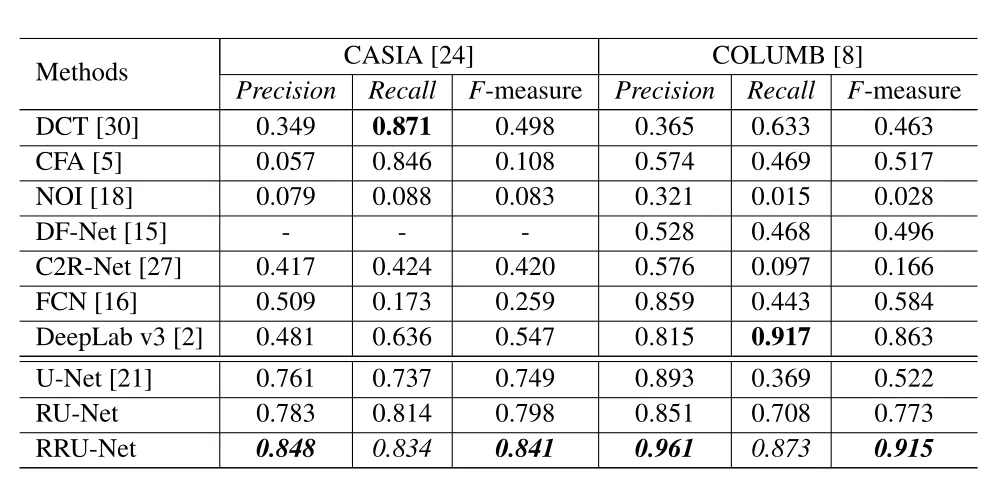
实验结果:RRU-NET 在 CASIA1.0 和 COLUMB 两个伪造图像数据集上的实验结果,CASIA 1.0 包括的篡改方式有拼接和复制粘贴攻击方式,但是本文只选取了其中的拼接攻击方式的数据集。COLUMB 是只包含拼接攻击的数据集。
简评:
- RRU-Net的主要创新体现在 Ringed Residual Structure,与其它方法不同是 RRU-Net 不直接设置检测伪造图像痕迹的特征,而是通过 residual feedback 机制让 CNN 自己去学习图片属性的差异特征,属于一种强化 CNN 学习的方法,并且经过实验证明了这种利用残差反馈方式自动学习图片属性差异的特征是有效的。
比赛
天池 - 伪造图像的篡改检测 - 长期赛
赛题背景
本次比赛的背景是由于随着各种P图工具的普及,篡改伪造出视觉无痕迹的假图门槛大幅降低,于是我们看到大量的假图用于散播谣言、编造虚假新闻、非法获取经济利益,更有甚者,还可能会被用来恶意地充当法庭证据。因此需要设计出能够准确检测出图像篡改区域的算法,避免假图造成的危害。
题目描述
比赛采用的数据为证书文档类图像,其中包括10类不同图像。
比赛的任务是通过提供的训练集学习出有效的检测算法,对测试集的伪造图像进行篡改定位。比赛的难点在于其分割区域是不能依靠边缘轮廓,因为篡改特征是偏向于弱信号特征(不可视的,跟内容特征弱相关),而且相对要分割出来的区域可能面积偏小。

比赛TOP3分享
参考资料:
[1]. 图像的篡改取证应用前景
[2]. PaperReadingGroup-2-篡改检测小综述
[3]. 图像篡改检测方法总结
[4]. 梁君牧-cnblog


最后更新: 2022年02月09日 18:15:47
本文链接: https://sanshui.findn.cn/post/3f292744.html
版权声明: 本作品采用 CC BY-NC-SA 4.0 许可协议进行许可,转载请注明出处!